
MEGAMATCHER ACCELERATOR SDK
SISTEMAS ESCALÁVEIS DE ALTA PRODUTIVIDADE
Projetos biométricos de grande escala podem ter requisitos específicos de desempenho do sistema. A família de produtos MegaMatcher Accelerator destina-se a projetos AFIS/ABIS de grande escala e oferece diferentes engines e edições de matching para alto desempenho durante grande número de solicitações.
O MegaMatcher Accelerator fornece escalabilidade fácil do sistema e permite iniciar um sistema biométrico a partir de uma única unidade no início, com ampliação adicional junto com os requisitos de capacidade e velocidade do projeto, expandindo o sistema em cluster e/ou atualizando as unidades usando motores com capacidades mais altas.
O MegaMatcher Accelerator foi projetado para uso em conjunto com outros componentes do MegaMatcher SDK, que fornecem captura de dados biométricos e extração de templates. Essas arquiteturas de sistema geralmente são usadas para projetos específicos:
- Criação de templates no lado do cliente e matching server-side – recomendado para AFIS, controle de fronteiras, vários sistemas de emissão de identidade, como passaportes, carteiras de identidade, registro de eleitores.
- Criação e matching de templates server-side – recomendado para serviços bancários online, serviços eletrônicos governamentais e outros sistemas de grande escala, nos quais as solicitações podem ser enviadas por qualquer dispositivo ou computador.
- Desduplicação após a coleta de dados de todos os usuários – recomendado para sistemas de emissão de RG, que coletaram dados biométricos anteriormente, como limpeza de cadastro de eleitores ou população.
Uma combinação das arquiteturas e componentes mencionados também pode ser usada em um sistema biométrico de grande escala para alcançar o desempenho e/ou disponibilidade ideais.
As licenças do software MegaMatcher Accelerator estão disponíveis para clientes novos e existentes do MegaMatcher Extended SDK.
O MegaMatcher Automated Biometric Identification System, uma solução multibiométrica integrada para projetos de identificação em escala nacional, também pode ser considerado. A solução pode ser customizada pela Neurotechnology para necessidades específicas do projeto.
Consulte o Consultor de produtos para descobrir quais produtos de Neurotechnology e arquiteturas de sistema melhor atenderão aos requisitos do seu projeto.
CRIAÇÃO DE TEMPLATES NO LADO DO CLIENTE E MATCHING SERVER-SIDE
Esta é a arquitetura mais utilizada para AFIS/ABIS, controle de fronteiras, vários sistemas de emissão de identidade, como passaportes, carteiras de identidade ou registro de eleitores. É adequado para vários sistemas, desde pequenos sistemas baseados em LAN até projetos em escala nacional. O gráfico abaixo mostra os principais componentes necessários para essa arquitetura.
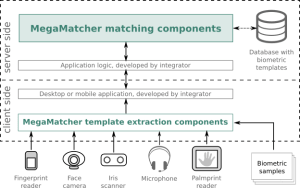
As unidades MegaMatcher Accelerator 13.0 prontas para uso são implantadas server-side e incluem engines biométricos para matching de templates de impressão digital, impressão palmar, face e íris, que podem ser facilmente dimensionados a qualquer momento para maior desempenho com base nos requisitos do projeto.
Os componentes de extração de templates do MegaMatcher são usados por integradores para desenvolver aplicativos móveis ou desktop client-side. Os componentes incluem todas as funcionalidades e desempenho necessários para captura de dados biométricos e extração de templates para enviá-los ao server-side. A implantação de aplicativos precisa apenas de licenças adicionais para os componentes correspondentes para cada computador ou dispositivo que executa o aplicativo.
CRIAÇÃO DE TEMPLATES E MATCHING SERVER-SIDE
Essa arquitetura foi projetada para ser usada em sistemas biométricos, que precisam processar solicitações de um número muito grande de clientes em cenários como banco on-line ou e-services governamentais, bem como outros sistemas de grande escala com um número muito grande de usuários. O gráfico abaixo mostra os principais componentes necessários para essa arquitetura.
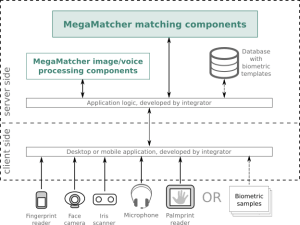
As unidades MegaMatcher Accelerator 13.0 prontas para uso são implantadas no server-side e incluem engines biométricos para matching de templates de impressão digital, impressão palmar, face e íris, que podem ser facilmente dimensionados a qualquer momento para maior desempenho com base nos requisitos do projeto.
Os componentes de extração de templates do MegaMatcher são implantados no server-side do sistema biométrico. Os integradores precisam desenvolver a lógica da aplicação, que irá operar com os componentes de extração de templates.
Os componentes de captura de dados biométricos do MegaMatcher fornecem a funcionalidade necessária para aplicativos client-side, que adquirem imagens biométricas de scanners ou câmeras e as enviam para o server-side para posterior extração de templates. A implantação de aplicativos precisa apenas de licenças adicionais para os componentes correspondentes para cada computador ou dispositivo que executa o aplicativo.
Os integradores também podem implementar a captura de imagens por conta própria e enviar imagens para a parte do servidor do sistema. Nesse caso, a implantação de aplicativos client-side não precisa de licenças para componentes de Neurotechnology.
DEDUPLICAÇÃO APÓS TODOS OS DADOS DE USUÁRIOS COLETADOS
Essa arquitetura é destinada a projetos de grande porte, como recenseamento eleitoral ou limpeza de cadastro populacional, quando a coleta de dados biométricos dos usuários é feita em duas etapas. Primeiro, os dados biométricos são capturados em vários sites, que não estão conectados ao banco de dados central. Posteriormente, os dados biométricos de todos os locais são enviados ao banco de dados central e verificados quanto a duplicatas. O gráfico abaixo mostra os principais componentes necessários para essa arquitetura.

As unidades MegaMatcher Accelerator 13.0 prontas para uso são implantadas no server-side e incluem engines biométricos para matching de templates de impressão digital, impressão palmar, face e íris, que podem ser facilmente dimensionados a qualquer momento para maior desempenho com base nos requisitos do projeto.
Os integradores precisarão desenvolver uma lógica de aplicativo simples para enviar os templates biométricos para desduplicação muitos para muitos e gerar o relatório de pesquisa de duplicatas.
Observe que essa tarefa de desduplicação de banco de dados requer muitos recursos computacionais, pois precisa comparar cada template biométrico com todos os outros templates biométricos em um banco de dados.
Os componentes de extração de templates do MegaMatcher podem precisar ser implantados no server-side, pois geralmente os dados biométricos são capturados como impressão digital, impressão da palma da mão, imagens de face ou íris, que precisam ser processadas em templates biométricos.
Os integradores precisam desenvolver a lógica da aplicação, que irá operar com os componentes de extração de template.
O Product Advisor pode fornecer uma estimativa de possíveis componentes e suas quantidades com base nos requisitos reais do projeto de pesquisa de duplicatas.
Você também pode considerar o MegaMatcher ABIS Cloud Service, que fornece resultados por um preço razoável sem a necessidade de desenvolver uma solução.
MATCHING ESCAVEL DO SERVER-SIDE COM MEGAMATCHER ACELERATOR
O MegaMatcher Accelerator 13.0 é uma solução para AFIS de grande escala e projetos multibiométricos, que está disponível nas versões Development Edition, Standard, Extended e Extreme.
Um sistema baseado no MegaMatcher Accelerator com uma única unidade pode ser ampliado adicionando mais unidades para criar um cluster e/ou atualizando para uma versão mais poderosa do MegaMatcher Accelerator.
O MegaMatcher Accelerator inclui o software necessário para permitir a escalabilidade do sistema, alta disponibilidade e tolerância a falhas.
O software MegaMatcher Accelerator 13.0 é fornecido com o MegaMatcher 13.0 Extended SDK.
A tabela abaixo compara diferentes versões da solução MegaMatcher Accelerator 13.0.
Desempenho e escalabilidade do MegaMatcher Accelerator 13.0
| Capacidade de banco de dados | Velocidade de matching | ||
| Cluster do MegaMatcher Accelerator 13.0 Development Edition com N unidades | Impressões digitais | N × 4,000,000 impressões digitais | N × 1,000,000 impressões digitais por segundo |
| Faces | N × 1,000,000 faces | N × 1,000,000 faces por segundo | |
| Íris | N × 5,000,000 íris | N × 1,000,000 íris por segundo | |
| Voz | N × 1,000,000 Voz | N × 200,000 Vozes por segundo | |
| Impressões palmares | N ×800,000 impressões palmares | N × 20,000 impressões palmares por segundo | |
| Cluster do MegaMatcher Accelerator 13.0 Standard com N unidades | Impressões digitais | N × 4,000,000 impressões digitais | N × 35,000,000 impressões digitais por segundo |
| Faces | N × 1,000,000 faces | N × 35,000,000 faces por segundo | |
| Íris | N × 5,000,000 íris | N × 70,000,000 íris por segundo | |
| Voz | N × 1,000,000 Voz | N × 10.000,000 Vozes por segundo | |
| Impressões palmares | N × 400,000 impressões palmares | N × 600,000 impressões palmares por segundo | |
| Cluster do MegaMatcher Accelerator 13.0 Extended com N unidades | Impressões digitais | N × 40,000,000 impressões digitais | N × 100,000,000 impressões digitais por segundo |
| Faces | N × 10,000,000 faces | N × 100,000,000 faces por segundo | |
| Íris | N × 50,000,000 íris | N × 200,000,000 íris por segundo | |
| Voz | N × 10,000,000 Voz | N × 30.000,000 Vozes por segundo | |
| Impressões palmares | N × 4,000,000 impressões palmares | N × 2,000,000 impressões palmares por segundo | |
| Cluster do MegaMatcher Accelerator 13.0 Extreme com N unidades | Impressões digitais | N × 160,000,000 impressões digitais | N × 1,200,000,000 impressões digitais por segundo |
| Faces | N × 40,000,000 faces | N × 1,200,000,000 faces por segundo | |
| Íris | N × 200,000,000 íris | N × 1,200,000,000 íris por segundo | |
| Voz | O engineVoice não está disponível no MegaMatcher Accelerator Extreme Edition | ||
| Impressões palmares | O engine Palmprint não está disponível no MegaMatcher Accelerator Extreme Edition | ||
Recomendações:
- O MegaMatcher Accelerator Development Edition não tem limitações no tamanho do cluster, mas em geral não faz sentido executar mais de 3 nós no cluster, pois todo o sistema custará como uma unidade MegaMatcher Accelerator Standard, proporcionando menor desempenho.
- O MegaMatcher Accelerator Standard não tem limitações no tamanho do cluster, mas em geral não faz sentido executar mais de 2 nós no cluster, pois todo o sistema custará como uma unidade MegaMatcher Accelerator Extended, proporcionando menor desempenho e capacidade.
- O MegaMatcher Accelerator Extended não tem limitações no tamanho do cluster, mas em geral não faz sentido executar mais de 4 nós no cluster, pois todo o sistema custará como uma unidade MegaMatcher Accelerator Extreme, proporcionando menor desempenho e capacidade.
- As velocidades correspondentes são fornecidas para motores de biometria simples. Se um template em um banco de dados contiver entradas multibiométricas, como impressões digitais e registros faciais pertencentes à mesma pessoa, os componentes correspondentes corresponderão a um número proporcionalmente menor de entradas de banco de dados biométricos de pessoas por segundo. Consulte o Product Advisor para obter os componentes correspondentes estimados com base no conteúdo do template biométrico e nos requisitos de desempenho.
- As unidades MegaMatcher Accelerator podem ser usadas para seleção rápida de candidatos usando íris, faces ou várias impressões digitais com validação de resultados adicionais usando engines de matching de impressão digital, face, íris e impressão de voz mais lentos que também estão incluídos no MegaMatcher Accelerator.
- Sistemas menores, que precisam corresponder até 200.000 impressões digitais, faces ou íris por segundo, podem ser baseados no Matching Server que está disponível no MegaMatcher SDK.
Além disso, dois ou mais clusters baseados no MegaMatcher Accelerator podem ser conectados juntos para um sistema de alta disponibilidade.
SOFTWARE DE CLUSTER ACELERADOR MEGAMATCHER
O MegaMatcher Accelerator inclui software de cluster, portanto, várias unidades MegaMatcher Accelerator 13.0 (nós de cluster) podem ser conectadas via rede a um cluster. Um cluster de aceleradores MegaMatcher pode ser ampliado a qualquer momento, atendendo aos requisitos de projeto em constante mudança, como um aumento no número de usuários ou ambiente de solicitação. O software de cluster fornece estes recursos avançados:
- Escalabilidade horizontal – alcançada pela adição de novos nós MegaMatcher Accelerator a um cluster. Como cada unidade opera em uma parte do banco de dados, um aumento no número de unidades MegaMatcher Accelerator resulta em uma matching mais rápida e um número maior de solicitações processadas.
- Por exemplo, existe um banco de dados com os dados biométricos de 15 milhões de pessoas (4 impressões digitais para cada usuário, 60 milhões de impressões digitais no total). O número de unidades necessárias do MegaMatcher Accelerator seria calculado desta forma:
- Todo o banco de dados deve caber na memória das unidades MegaMatcher Accelerator. Uma única unidade MegaMatcher Accelerator 13.0 Extended armazena 40 milhões de impressões digitais, portanto, seriam necessárias 2 unidades para armazenar o banco de dados de 60 milhões de impressões digitais.
- O tempo de resposta para uma solicitação de identificação deve satisfazer os requisitos do projeto. Uma única unidade MegaMatcher Accelerator 13.0 Extended corresponde a 27 milhões de templates de impressão digital por segundo no modo 4 para muitos se o projeto requer receber uma resposta a uma solicitação de identificação em 1 segundo, portanto, duas unidades atenderão aos requisitos do projeto para tempo de resposta.
- A quantidade de solicitação de horário de pico deve atender aos requisitos do projeto. Por exemplo, o projeto espera que possa haver até 15.000 solicitações de identificação por hora. Uma única unidade MegaMatcher Accelerator 13.0 Extended corresponde a 27 milhões de templates de impressão digital por segundo no modo 4-para-muitos, portanto, será capaz de processar 6.480 solicitações por hora com o banco de dados de amostra de 15 milhões de templates. Um cluster de 3 unidades MegaMatcher Accelerator 13.0 Extended será necessário para processar o número esperado de solicitações de identificação neste caso.
- Escalabilidade vertical – geralmente alcançada atualizando para uma edição mais poderosa do MegaMatcher Accelerator. Por exemplo, uma única unidade MegaMatcher Accelerator Extended fornece matching biométrica quase três vezes mais rápida e pode armazenar dez vezes mais templates biométricos em comparação com uma única unidade MegaMatcher Accelerator Standard.
- Tolerância a falhas – um cluster de aceleradores MegaMatcher pode restaurar sua operação após um ou mais nós deixarem o cluster de forma anormal por qualquer motivo, como falha de hardware ou rede, problema de software etc. O software do cluster detecta automaticamente os eventos de falha e redistribui os dados de os nós com falha entre os nós ativos para manter todo o banco de dados disponível para solicitações de identificação. Naturalmente, essa funcionalidade requer um número maior de nós do que o mínimo necessário para o desempenho e/ou capacidade especificados, portanto, há alguma reserva para substituir os nós com falha.
- Alta disponibilidade – dois clusters de aceleradores MegaMatcher podem ser executados em paralelo, mantendo os dados sincronizados entre os clusters. Essa configuração fornece o dobro do desempenho enquanto os dois clusters operam normalmente. Se um cluster ficar indisponível, o outro continuará operando e fornecerá o nível padrão de desempenho.
- Arquitetura ponto a ponto – os nós do cluster distribuem automaticamente o banco de dados biométrico e as solicitações dos clientes entre si. Essa arquitetura significa que não há nó mestre no cluster, portanto, não há problemas com um único ponto de falha ou gargalo.
- Operação ininterrupta – não há tempo de inatividade enquanto novos nós estão sendo adicionados ao cluster ou um dos nós desaparece. A operação normal